
Build@Mercari from Week 2 to 4: Deep Dive into Data Structure and Algorithm #BuildAtMercari



Hi, there! This is Mark (@TangoEnSkai) from Mercari’s Backend Engineering Team.
Every Wednesday night, our Build@Mercari participants and the Build team join the training. Today, I would like to share what we have discussed and covered from week two to four.
Check out this article for our first report.
In this Article
-

Mark HahnJun “Mark” Hahn is currently a Software Engineer for the Home & Search Team, under Backend & SRE Team, Engineering Division, Mercari JP. He joined Mercari Inc., as a new grad in April 2019. In the past, he has studied multidisciplinary fields such as computer science, sociology, psychometrics, and liberal arts. Although his experience is mostly based on theoretical studies, his interests are in practical contributions to our daily lives through technology. As a software engineer, his current focus is on Golang, Microservices Architecture, Agile Software Development, and a little bit of functional programming.

Here are the topics and subjects we covered:
Week 2: Data structure I
Week 3: Data structure II
Week 4: Algorithms
Week Two: Data Structure I
On the first week of June, we started the first half lecture about data structures. This lecture was given by Hunter who is a software engineer working in one of the backend teams. The main topics covered in this session are below:

One of the purposes of this program is giving a chance to learn essential topics of computer science (CS) for people who do not have a CS background. We actually have many participants who have backgrounds other than CS, so we decided to cover a little bit more on the fundamentals of computing, so that they are able to learn more about how to program in depth.
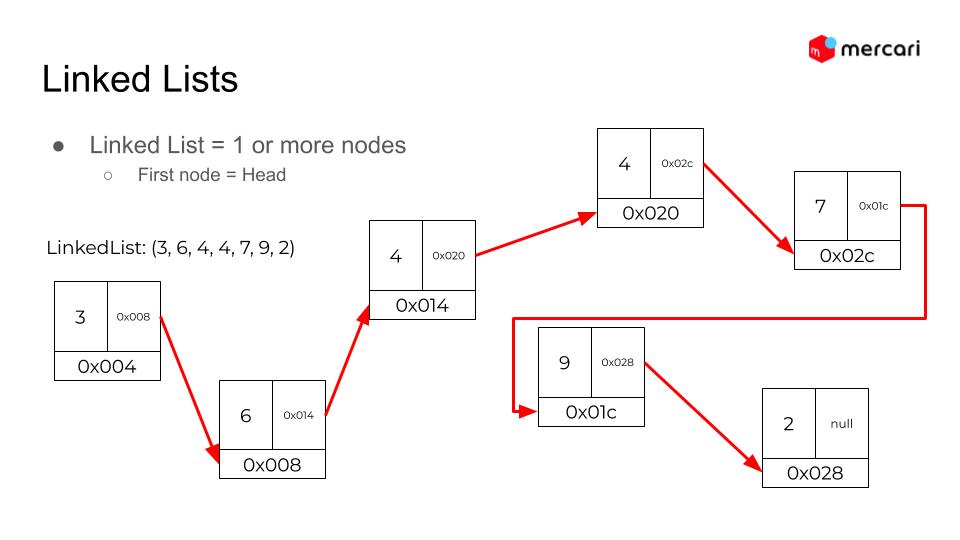
Learning about low level memory representation is not easy even for first and second year CS students, but thanks to Hunter’s nice explanation about how it works internally, we hope all of the participants were able to get the idea of the concept and they could use this theory and concept when they build the real application in the future!
After we talked about linked list, we had a break time and started to introduce “stack”.
We discussed two different ways of stack implementations:
・ Array Implementation
・ Linked List Implementation
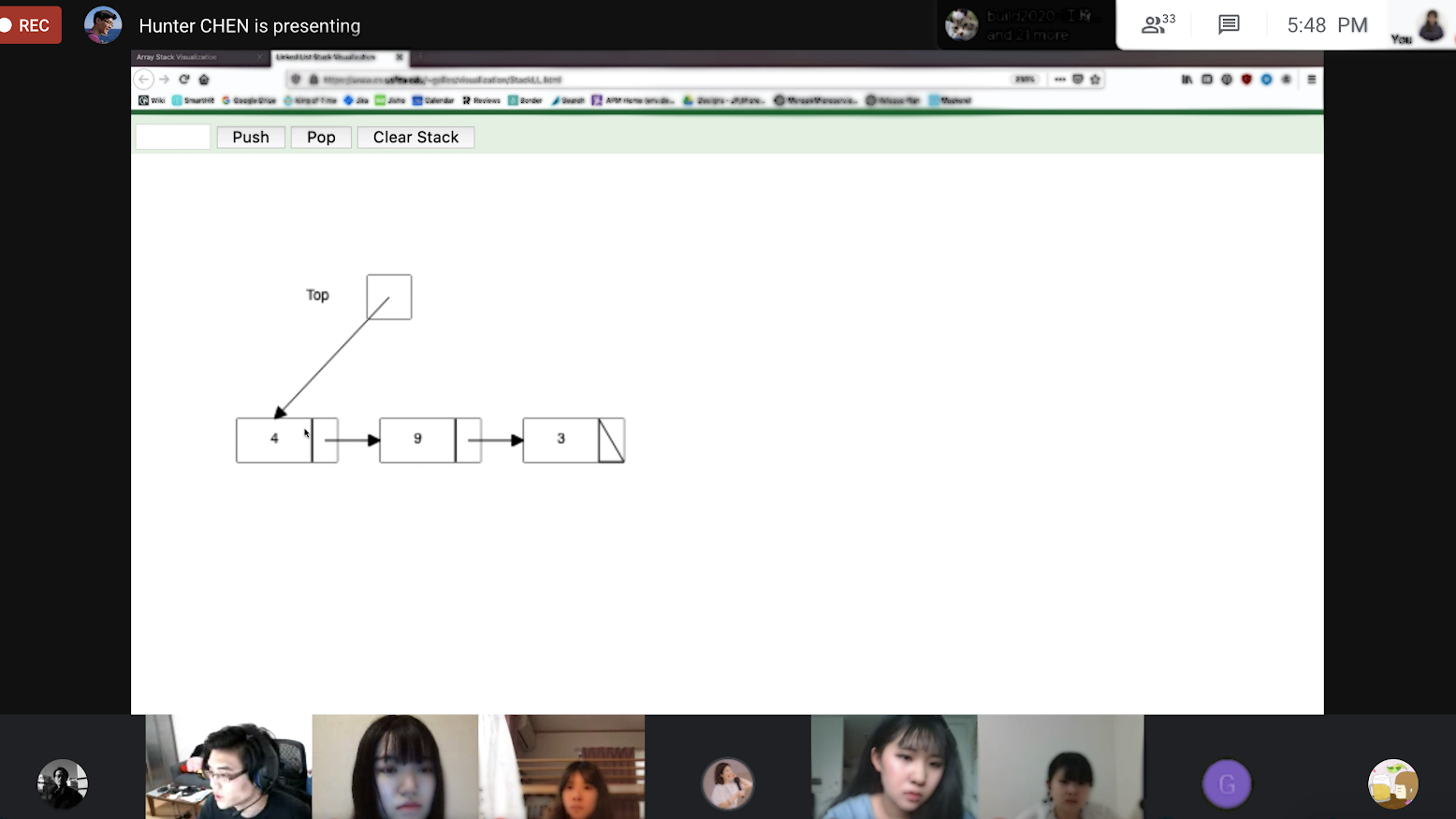 Hands-on Explanation about Stack Implementation with Visualization
Hands-on Explanation about Stack Implementation with Visualization
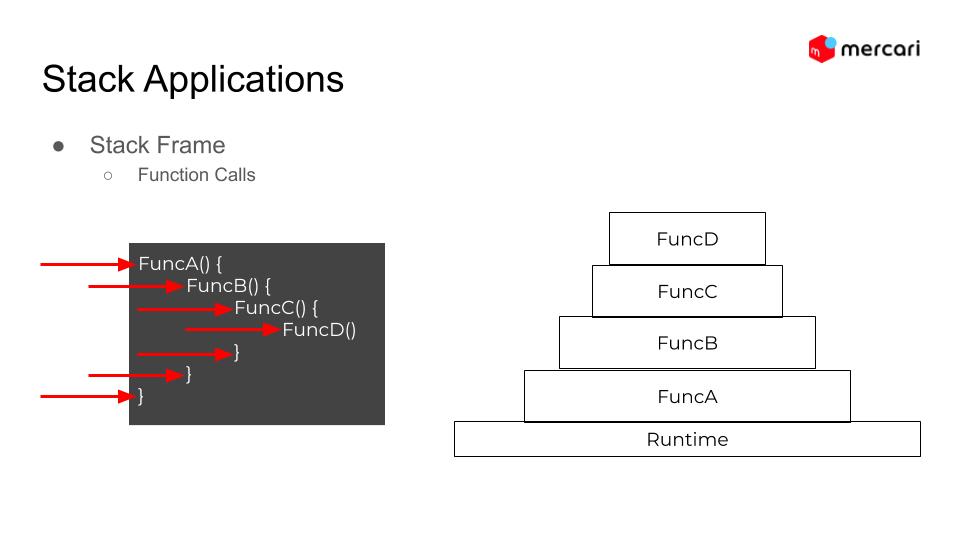
We also covered not only the basic stack implementation but also on how it works at the application level. Here is one of the examples that how a function called by employing the concept of stack:
The last topic of this week’s lecture was “queue”. The introduction of the queue was basically following the same structure of how we explained about the “stack” so that the participants could compare and learn together easily.
There are basic behaviors of queue and these were also explained from the concept and theory to the actual implementation.
We have discussed about two different way of queue implementations:
・ Array Implementation
・ Linked List Implementation
As an example of the usage of queue, we discussed a little bit about CPU scheduling.
In detail, with the actual example of Shortest Job First (SJF) scheduling, the usage of queue in operating systems and how it handles the given processes
View the full content of our Week 2 class
Week Three: Data Structures II
We also covered data structures in the he third week, however the topics were more advanced such as:
・ Tree
・ Graph
In addition, at the end of the lecture, we had a group exercise!
The instructor was tarotaro0 who is a software engineer working in a backend, notification team. The goal of this week’s lecture was to understand the characteristics of each data structure and be able to discuss design. But, we did not aim for the basics of each data structure and detailed implementation and hands-on exercises.

After we discussed the basic concept of the hash table, we talked about the internal structure of the hash table.
We also covered very important hash table topics such as:
・ Hash Function
・ Collision
・ Benefits with Hash Table with Search Examples
・ Real World Examples
Trees were the second topic of this week!
After introducing different types of trees , we presented our company’s team structure to explain the benefit of trees. There are:
・ Representation of Hierarchical Structure
・ Representation of Branched Structure
・ Human-Friendly: easy to understand intuitively
・ Easy to Organize/Manage Data
This data structure is frequently used for computer systems. Directories (or as known as folders) can be one of the hierarchical representations of data in tree structure.

Web page and Document Object Model (DOM) was given as another example. DOM is actually one of the topics we are going to discuss in our front-end training week! I hope people can remember this topic when they learn DOM very soon.
Furthermore, we talked about the usage of tree structure with our Mercari application’s case. We have many different categories, and they are defined as three layers: Large, Medium, Small. These layers of categories are a range of the scope which means that large categories have broader categorization.
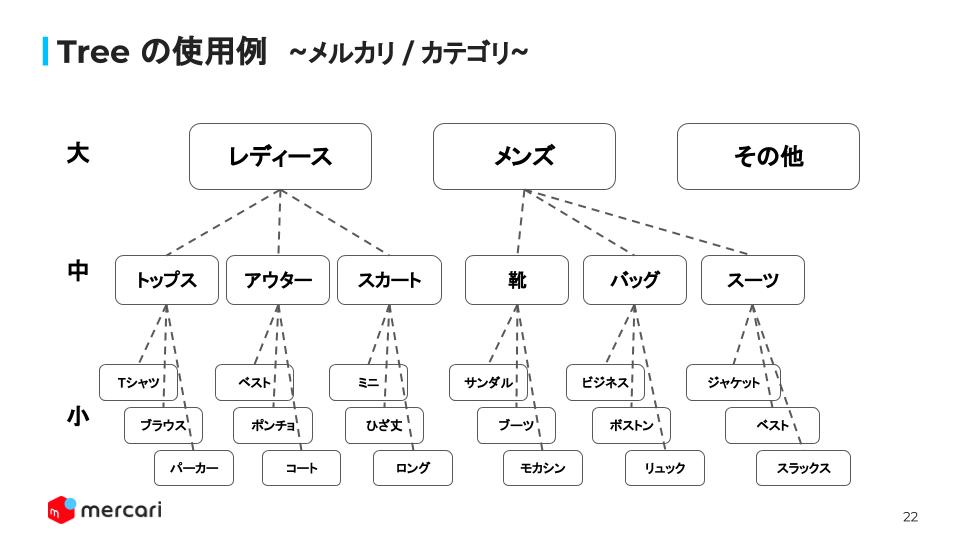
For example we have a large category scope as ladies’ and men’s. Each category has medium categories and the entire categorization follows the tree structure.
Other examples were given such as: database index, b-tree. Then, we introduced our last topic “graph”.
Like the hash table and tree session, we talked about graph’s:
・ Definition
・ Variations / types
・ Benefits
・ Examples
In this lecture we introduced:
・ Directed/Undirected graph
・ Weighted graph
As we mentioned from this slide above, graphs can have these benefits:
・ Representation of Relationship between Nodes
・ Data Relationship and Expression
・ Tree: hierarchy with parent and child
・ Graph: can define a wider range of relationships
For examples of the usage of graph data structure, our Microservice migration, Facebook’s friend connections, PageRank algorithm of Google Search Engine, Subway/Metro systems,
Now we have covered the hash table, tree, and graph! At the end of this week’s session, we had group work and short presentations! The topic was “Let’s identify the infection route of C virus”. The given conditions were:
・ C virus infects people who have contacted with infected people with a certain probability
We have the lists of
・ Previously infected people
・ People who were Contacted by infected persons and people who were recursively contacted
The given problems were:
Consider a system that identifies the infection route of a newly infected person X
Think more realistically and imagine different patterns of infections
You can freely add conditions if necessary for thinking/reasoning
We believe that being able to think about better system designs after learning data structures is one of the essential skills that good software engineers should have rather than simply learning how to implement in a certain way with specific programming languages. At the same time, thinking about the real world examples are always required at workspaces, so we hope this type of exercise can enrich their problem solving skills. Of course, we had homework to have real programming experience by implementing an English dictionary.
View the full content of our Week 3 class
Week Four: Algorithms
This week, we discussed algorithms that are used in Mercari. We took one concrete example of the use case which is closely related to Image Search Function. the goals and no-goals of this weeks are:
Ability to understand algorithms
Ability to identify computational costs
Here are the topics covered:
Algorithms with image search examples

At the beginning of the lecture, we showed how data flows for the image search functionality. We use Neural Network to extract certain characteristics and attributes as a vector, and add those vectors to closer search indices. This is closely related to one of the algorithm techniques to find the nearest neighbor search.
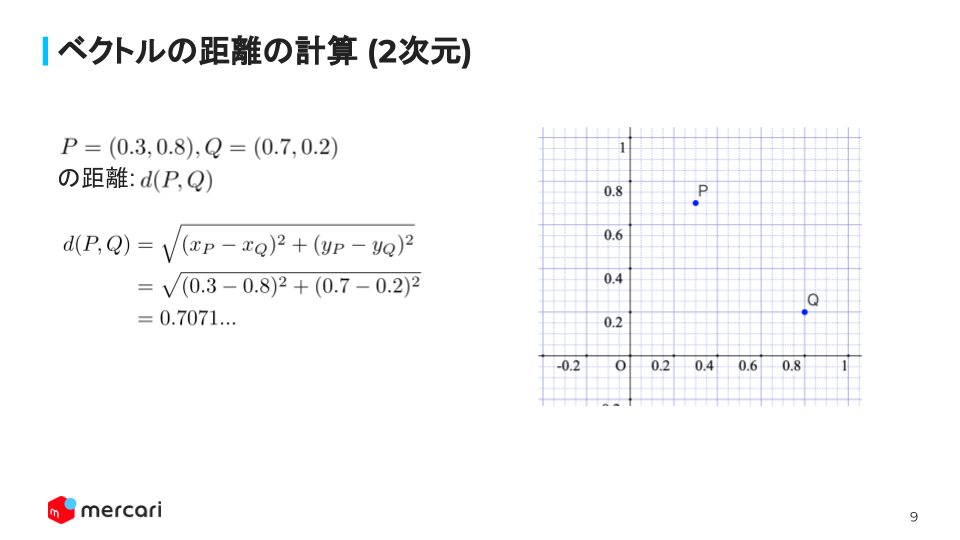
In order to calculate the vectors, we introduced the very simple mathematical example:
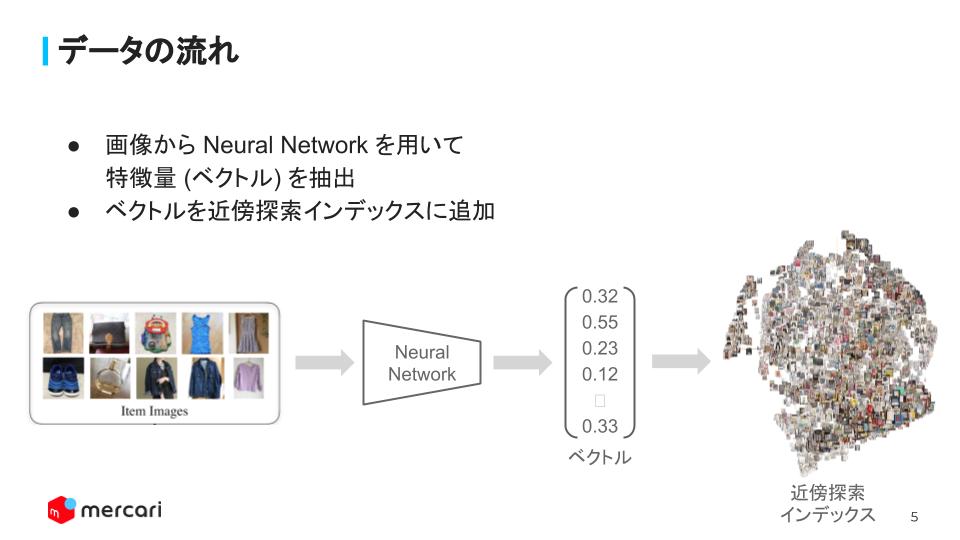
And the concept is expanded to N-Dimension.
After that, we discussed some questions. One of them was for a search query in a database and its computational complexities, such as time and space when we calculate:
・ Distance between a set of feature vectors
・ Distance to each of the N feature vectors
However, in the real world, we have very complex vector spaces and in order to run the calculator in an efficient way, we need additional techniques because it may slow our search engine performance. Therefore, we were also introducing how to speed up these calculations.
View the full content of our Week 4 class (Japanese)
In the next few weeks we are going to cover the frontend and backend, we will be reporting again here on Mercan so please stay tuned. See you again for more #MercariDays!
 Quick Reads ✨
Quick Reads ✨


・ Stacks
・ Queues